How to run an existing Jenkins pipeline continuously using recursion
Reading time: 4 minutes, 6 seconds
In this post, I will show you a simple way to take an existing Jenkins (test) pipeline and run it continuously until it reaches a maximum number of runs. We use this to run our complete test suite continuously during the night in order to gather failure data.
Demo pipeline
Let's take a demo script for a functional Jenkins pipeline:
#!/usr/bin/env groovy
pipeline {
agent any
stages {
stage('Demo Pipeline') {
steps {
script {
sh script: """
echo "This is some script!"
""", label: "Some script"
}
}
}
}
}When this is running, it just echoes "This is some script!" to the console - this could of course be any kind of (shell) script that your pipeline contains:

So far it has only one single stage:
In order to make this one recursive, we need to add some things.
1. Add a counter
To keep track of the current number of runs, we need to introduce a counter to our pipeline that is persistent across all pipeline runs. An easy way to do this is by using a parameter:
parameters {
string(name: 'PIPELINE_RUN', defaultValue: '1', description: 'Current run count of this job.')
}By giving it a default value, we can be sure it is set to 1 even if this pipeline is triggered by a cronjob without explicitly setting this parameter.
Let's also add this counter to our script block:
script {
currentRun = params.PIPELINE_RUN as int
sh script: """
echo "This is some script for run ${currentRun}!"
""", label: "Some script"
}We cast it to an int (params.PIPELINE_RUN as int) since we want to increase it later. Additionally, we add it to our echo command to check it is working correctly.
If we run it now, we have to use "Build with Parameters" because of the new parameter we introduced:

We can directly click "Build" here since our PIPELINE_RUN parameter is set to a default value.
This is the current output:

2. Add a post block
In the next step, we add a post block to check the current number of runs, compare it to the maximum and retrigger the same pipeline if the maximum number is not reached yet.
This block is added after the stages block - for now it just contains some simple code to sleep for 5 seconds, increase the run counter and print Checking next trigger for run ${currentRun}... so we can verify that the increase of our counter variable is working:
post {
always {
script {
sleep(5)
currentRun++
println "Checking next trigger for run ${currentRun}..."
}
}
}This tells Jenkins to always execute this script after (post) the pipeline stages.
If we run the pipeline now, we can see that it now has an additional "Declarative: Post Actions" stage that has a 5 second run time:
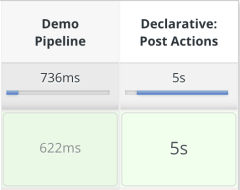
Also, script output Checking next trigger for run 2... of this stage is correct!
3. Add the re-run logic
Now we need to add the logic for retriggering the same pipeline if the run counter has not reached our maximum yet. This is done in the same post block as before:
if (currentRun <= 3) {
println "Triggering run ${currentRun}..."
} else {
println "Stopping execution - maximum runs reached."
}This is the condition that checks if this pipeline is run for the third time. If no, it should be retriggered. Otherwise, we just print "Stopping execution - maximum runs reached.".
Let's run this code again just to be sure:

It prints "Triggering run 2..." as expected.
4. Add the retrigger functionality
The last step is retriggering itself but with the updated counter variable. This is done with this small block of code:
build job: "${JOB_NAME}",
parameters: [[$class: 'StringParameterValue', name: 'PIPELINE_RUN', value: String.valueOf(currentRun)]],
wait: falseIt means:
- Build the job that has the current job name (the
${JOB_NAME}parameter stores the current one automatically) - Pass the string parameter named
PIPELINE_RUNwith the value of thecurrentRunvariable along with the call - Don't wait for the newly triggered job (this is very important, otherwise pipelines will keep piling up and stay in a waiting state)
The result
If we run this pipeline now, it works as expected:
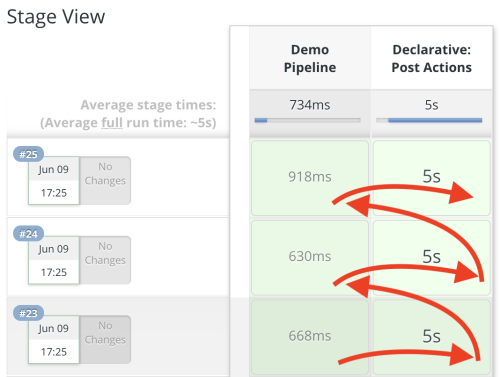
We have three consecutive runs that trigger each other (I added some arrows to make it clear).
The complete script
#!/usr/bin/env groovy
pipeline {
agent any
parameters {
string(name: 'PIPELINE_RUN', defaultValue: '1', description: 'Current run count of this job.')
}
stages {
stage('Demo Pipeline') {
steps {
script {
currentRun = params.PIPELINE_RUN as int
sh script: """
echo "This is some script for run ${currentRun}!"
""", label: "Some script"
}
}
}
}
post {
always {
script {
sleep(5)
currentRun++
println "Checking next trigger for run ${currentRun}..."
if (currentRun <= 3) {
println "Triggering run ${currentRun}..."
build job: "${JOB_NAME}",
parameters: [[$class: 'StringParameterValue', name: 'PIPELINE_RUN', value: String.valueOf(currentRun)]],
wait: false
} else {
println "Stopping test execution - maximum runs reached."
}
}
}
}
}